


Gerd Gigerenzer
bSI Epistemology Camp: 2024 At his talk at the Broken Science Epistemology Camp in March 2024, psychologist Gerd Gigerenzer addresses what he calls ‘mindless statistics.’ Rather than think critically about the implications, impact, and meaning of studies, researchers are stuck in a system wh...

Broken Science
April 16, 2024 article from the Brownstone Institute.Frequently unreported or classified under a different cause, deaths from prescription drugs are on the rise. Peter Gøtzsche tallies up the totals and finds the risks to be higher than previously thought.“Many people die because of errors, e.g. ...

Malcolm Kendrick
By Malcolm KendrickA few years back I was told that, in the statin clinical trials, the rate of adverse effects was always the same for the placebo, and the statin. No matter the absolute rate. This was also true for the rate of participants withdrawing from the trials. Always the same between the s...
Broken Science
April 2, 2024 article in Cancer Commons.Thomas Seyfried and his colleagues at Boston College are known for their stance on cancer being a metabolic disease, rather than a genetic one. Despite the expansion of the field of cancer genomics, Seyfried maintains that the metabolic view offers a better ex...

Russell Berger
By Russell BergerIn the 1964 suspense film 36 hours, U.S. Army Major Jefferson Pike (played by James Garner), is kidnapped by Nazis on the eve of the Allied invasion of Normandy. Pike wakes up in what appears to be a U.S. Army hospital, surrounded by soldiers and nurses that all appear to be red-blo...

Broken Science
April 3, 2024 article by Sasha Chavkin, Caitlin Gilbert, Anjali Tsui and Anahad O’Connor in The Washington Post.By sponsoring dietitians on social media and funding their own studies, General Mills and other cereal brands are shifting the narrative away from the detrimental physical effects of a h...

Greg Glassman
bSI Epistemology Camp: 2024 Greg Glassman kicked off the 2024 BSI Epistemology Camp with this presentation. Greg’s talk centers around the ‘breaking point’ from modern science to post modern science. Condemning the rise in popularity of philosophers of science like Karl Popper, Paul Feyera...

Broken Science
March 26, 2024 Article by Sanjana Friedman on Pirate Wires.The state's math framework is strongly influenced by the academic work of Jo Boaler, now accused of significantly distorting citations in research underpinning the framework..“Boaler first made a name for herself in the mid-2000s by advoca...

William Briggs
By William BriggsA new study came out that claimed intermittent fasting is bad for you. This shocked a lot of people. Here’s one of the hot headlines: “8-hour time-restricted eating linked to a 91% higher risk of cardiovascular death“.Ninety one percent? Dude. That’s a lot. Makes it sound l...

Malcolm Kendrick
By Malcolm KendrickAs everyone knows, a placebo is an inactive ‘sugar’ pill. Except when it isn’t. Which is almost always. Here, from 2010, is an article about research on placebos carried out by Dr Beatric Golomb [1]."What rules are there about what goes into placebos?Despite carrying moniker...
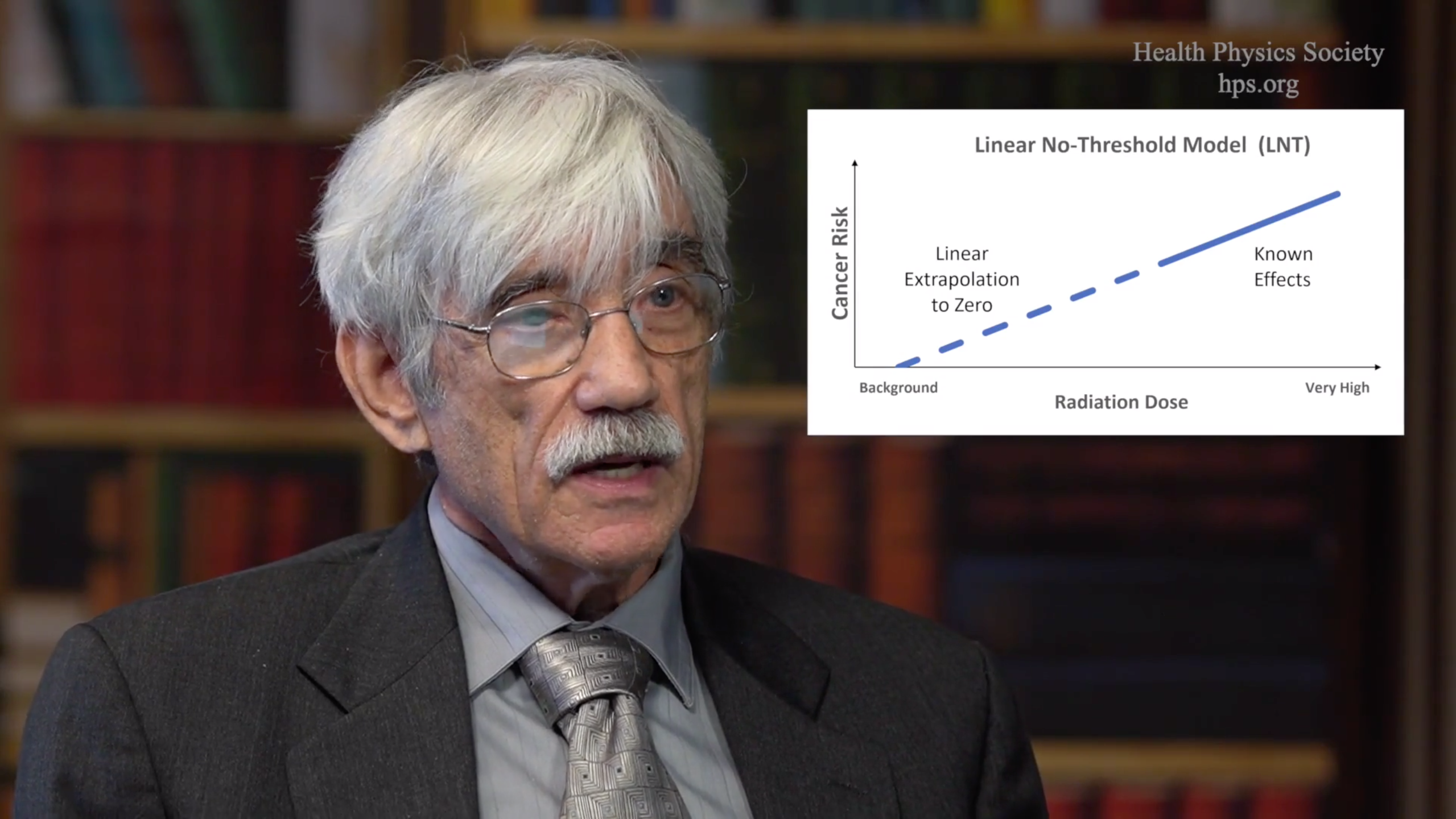
Broken Science
March 07, 2024 commentary in the Journal of Occupational and Environmental Hygiene and a documentary by the Health Physics Society.From corruption in governing bodies to deliberate misrepresentations by researchers, this series takes the first steps to correct the scientific record in the field of c...

Emily Kaplan
Februaury 28, 2024 episode of the Dr. Drew PodcastDr. Drew and Emily call attention to the flaws in the current state of modern science. Emily and Drew discuss the Dana-Farber scandal, the cost/benefit of going to college, the do-or-die culture in science, and the lack of curiosity among journalists...
Gerd Gigerenzer
bSI Epistemology Camp: 2024 At his talk at the Broken Science Epistemology Camp in March 2024, psychologist Gerd Gigerenzer addresses what he calls ‘mindless statistics.’ Rather than think critically about the implications, impact, and meaning of studies, researchers are stuck in a system wh...
Broken Science
April 16, 2024 article from the Brownstone Institute.Frequently unreported or classified under a different cause, deaths from prescription drugs are on the rise. Peter Gøtzsche tallies up the totals and finds the risks to be higher than previously thought.“Many people die because of errors, e.g. ...
Malcolm Kendrick
By Malcolm KendrickA few years back I was told that, in the statin clinical trials, the rate of adverse effects was always the same for the placebo, and the statin. No matter the absolute rate. This was also true for the rate of participants withdrawing from the trials. Always the same between the s...
Broken Science
April 2, 2024 article in Cancer Commons.Thomas Seyfried and his colleagues at Boston College are known for their stance on cancer being a metabolic disease, rather than a genetic one. Despite the expansion of the field of cancer genomics, Seyfried maintains that the metabolic view offers a better ex...
Russell Berger
By Russell BergerIn the 1964 suspense film 36 hours, U.S. Army Major Jefferson Pike (played by James Garner), is kidnapped by Nazis on the eve of the Allied invasion of Normandy. Pike wakes up in what appears to be a U.S. Army hospital, surrounded by soldiers and nurses that all appear to be red-blo...
Broken Science
April 3, 2024 article by Sasha Chavkin, Caitlin Gilbert, Anjali Tsui and Anahad O’Connor in The Washington Post.By sponsoring dietitians on social media and funding their own studies, General Mills and other cereal brands are shifting the narrative away from the detrimental physical effects of a h...
Greg Glassman
bSI Epistemology Camp: 2024 Greg Glassman kicked off the 2024 BSI Epistemology Camp with this presentation. Greg’s talk centers around the ‘breaking point’ from modern science to post modern science. Condemning the rise in popularity of philosophers of science like Karl Popper, Paul Feyera...
Broken Science
March 26, 2024 Article by Sanjana Friedman on Pirate Wires.The state's math framework is strongly influenced by the academic work of Jo Boaler, now accused of significantly distorting citations in research underpinning the framework..“Boaler first made a name for herself in the mid-2000s by advoca...
William Briggs
By William BriggsA new study came out that claimed intermittent fasting is bad for you. This shocked a lot of people. Here’s one of the hot headlines: “8-hour time-restricted eating linked to a 91% higher risk of cardiovascular death“.Ninety one percent? Dude. That’s a lot. Makes it sound l...
Malcolm Kendrick
By Malcolm KendrickAs everyone knows, a placebo is an inactive ‘sugar’ pill. Except when it isn’t. Which is almost always. Here, from 2010, is an article about research on placebos carried out by Dr Beatric Golomb [1]."What rules are there about what goes into placebos?Despite carrying moniker...
Broken Science
March 07, 2024 commentary in the Journal of Occupational and Environmental Hygiene and a documentary by the Health Physics Society.From corruption in governing bodies to deliberate misrepresentations by researchers, this series takes the first steps to correct the scientific record in the field of c...
Emily Kaplan
Februaury 28, 2024 episode of the Dr. Drew PodcastDr. Drew and Emily call attention to the flaws in the current state of modern science. Emily and Drew discuss the Dana-Farber scandal, the cost/benefit of going to college, the do-or-die culture in science, and the lack of curiosity among journalists...
Gerd Gigerenzer
bSI Epistemology Camp: 2024 At his talk at the Broken Science Epistemology Camp in March 2024, psychologist Gerd Gigerenzer addresses what he calls ‘mindless statistics.’ Rather than think critically about the implications, impact, and meaning of studies, researchers are stuck in a system wh...
Broken Science
April 16, 2024 article from the Brownstone Institute.Frequently unreported or classified under a different cause, deaths from prescription drugs are on the rise. Peter Gøtzsche tallies up the totals and finds the risks to be higher than previously thought.“Many people die because of errors, e.g. ...
Malcolm Kendrick
By Malcolm KendrickA few years back I was told that, in the statin clinical trials, the rate of adverse effects was always the same for the placebo, and the statin. No matter the absolute rate. This was also true for the rate of participants withdrawing from the trials. Always the same between the s...
Russell Berger
By Russell BergerIn the 1964 suspense film 36 hours, U.S. Army Major Jefferson Pike (played by James Garner), is kidnapped by Nazis on the eve of the Allied invasion of Normandy. Pike wakes up in what appears to be a U.S. Army hospital, surrounded by soldiers and nurses that all appear to be red-blo...
Greg Glassman
bSI Epistemology Camp: 2024 Greg Glassman kicked off the 2024 BSI Epistemology Camp with this presentation. Greg’s talk centers around the ‘breaking point’ from modern science to post modern science. Condemning the rise in popularity of philosophers of science like Karl Popper, Paul Feyera...
William Briggs
By William BriggsA new study came out that claimed intermittent fasting is bad for you. This shocked a lot of people. Here’s one of the hot headlines: “8-hour time-restricted eating linked to a 91% higher risk of cardiovascular death“.Ninety one percent? Dude. That’s a lot. Makes it sound l...
Malcolm Kendrick
By Malcolm KendrickAs everyone knows, a placebo is an inactive ‘sugar’ pill. Except when it isn’t. Which is almost always. Here, from 2010, is an article about research on placebos carried out by Dr Beatric Golomb [1]."What rules are there about what goes into placebos?Despite carrying moniker...
Broken Science
March 07, 2024 commentary in the Journal of Occupational and Environmental Hygiene and a documentary by the Health Physics Society.From corruption in governing bodies to deliberate misrepresentations by researchers, this series takes the first steps to correct the scientific record in the field of c...
Emily Kaplan
Februaury 28, 2024 episode of the Dr. Drew PodcastDr. Drew and Emily call attention to the flaws in the current state of modern science. Emily and Drew discuss the Dana-Farber scandal, the cost/benefit of going to college, the do-or-die culture in science, and the lack of curiosity among journalists...
Emily Kaplan
On February 27th, BSI Co-Founder and CEO Emily Kaplan was interviewed by Dr. Ken Berry. During the livestream, the two discussed diabetes, misleading health studies, and issues with medical journalism.Ken D Berry, MD is a Family Physician, Speaker and Author based near Nashville, Tennessee, U.S. He ...

Emily Kaplan
On February 15th, Co-founder and CEO of The Broken Science Initiative, Emily Kaplan, went onto the B FIT Podcast with Connor Murphy. Connor Murphy is a celebrity trainer, Crossfit seminar staff, and trainer at Big Night Fitness.On the show Emily dives into the fundamentals of the initiative. From th...

Malcolm Kendrick
By Malcolm KendrickIn previous articles (1, 2, 3, 4) I have been analyzing the FOURIER study in some detail, and I will continue to do so here. Not because this research paper represents some weird outlier—the worst, of the worst, of the worst research ever. But because it is an excellent case stu...
Russell Berger
By Russell BergerIn the 1964 suspense film 36 hours, U.S. Army Major Jefferson Pike (played by James Garner), is kidnapped by Nazis on the eve of the Allied invasion of Normandy. Pike wakes up in what appears to be a U.S. Army hospital, surrounded by soldiers and nurses that all appear to be red-blo...
Broken Science
April 3, 2024 article by Sasha Chavkin, Caitlin Gilbert, Anjali Tsui and Anahad O’Connor in The Washington Post.By sponsoring dietitians on social media and funding their own studies, General Mills and other cereal brands are shifting the narrative away from the detrimental physical effects of a h...
William Briggs
By William BriggsA new study came out that claimed intermittent fasting is bad for you. This shocked a lot of people. Here’s one of the hot headlines: “8-hour time-restricted eating linked to a 91% higher risk of cardiovascular death“.Ninety one percent? Dude. That’s a lot. Makes it sound l...
Emily Kaplan
On February 27th, BSI Co-Founder and CEO Emily Kaplan was interviewed by Dr. Ken Berry. During the livestream, the two discussed diabetes, misleading health studies, and issues with medical journalism.Ken D Berry, MD is a Family Physician, Speaker and Author based near Nashville, Tennessee, U.S. He ...

Russell Berger
By Russell BergerOn November 30th, JAMA Network Open published Cardiometabolic Effects of Omnivorous vs Vegan Diets in Identical Twins. The study has a lot of things going for it: A prestigious research team from Stanford Medical school, the growing popularity of vegan diets, and the novelty of id...

Broken Science
This editorial commentary by Gerd Gigerenzer and Julian Marewski discusses the dream of a universal method of inference in science. The great mathematician Gottfried Wilhelm Leibniz dreamed of a universal calculus in which all ideas could be represented by symbols and discussed without bickering. He...

Emily Kaplan
https://youtu.be/dBV3tYTUr5QEmily explains the strengths, weaknesses, and ways to interpret observational studies. These types of studies can be useful for identifying links between things, and then generating hypotheses. However, the results of any observational study are strictly corollary, and do...

Broken Science
Oct. 2023 article from Nature. A research-rating system has identified gaps in studies that assess the connection between diet and various health risks. “We have evidence that underpowered clinical studies, lacking necessary controls to make sense of the data, are not helping. If funders do not...
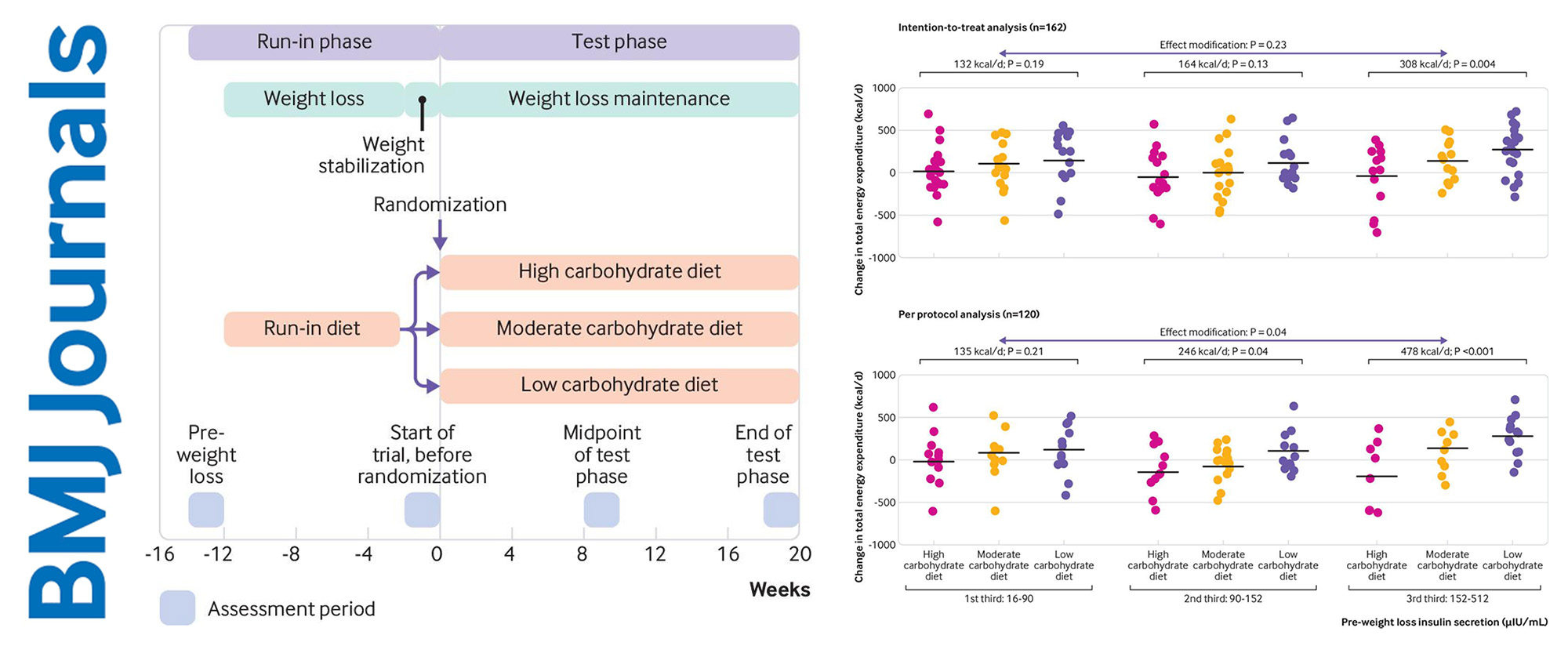
Broken Science
2023 article from The BMJ. In this 2018 trial, participants lost 12% bodyweight through caloric restriction, and were then given a high, medium, or low carb diet. Those on the high and medium carb diets had to maintain a much more calorically restricted diet in order to maintain their body weight....
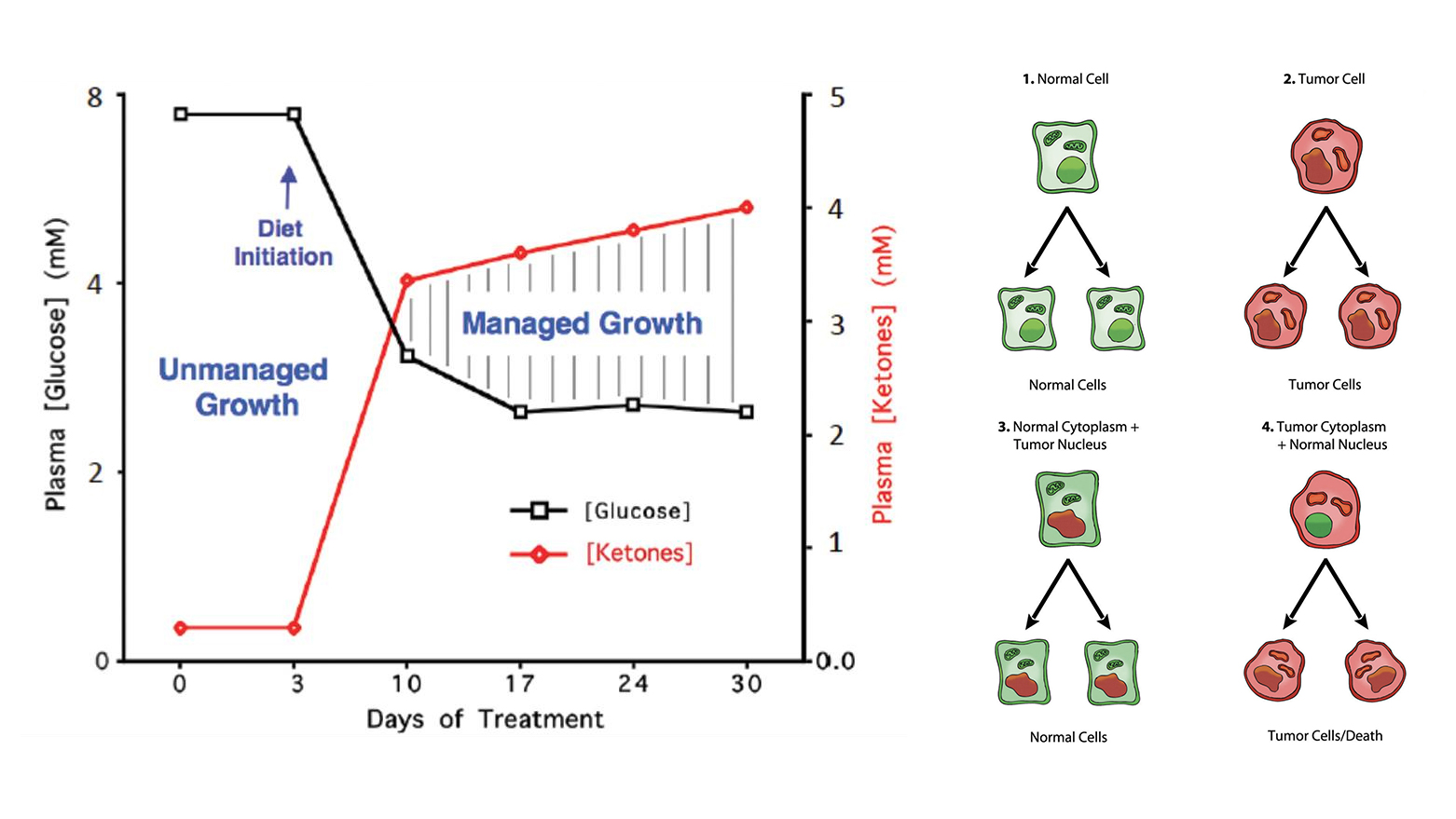
Broken Science
This literature review serves as an in-depth exploration into the metabolic underpinnings of cancer. The authors present a departure from conventional cancer treatments like chemotherapy and radiation and instead advocate for a multi-faceted approach, comprising of nutritional ketosis, metabolic dru...

Maryanne Demasi, PhD
“America has the highest chronic disease burden in the world,” lamented Robert F Kennedy Jr during a speech in April this year, prompting him to make a bold promise to the American people.“If I have not significantly dropped the level of chronic disease in our children by the end of my first...

Greg Glassman
Greg Glassman, Mark Bell, Nsima Inyang, and Andrew Zaragoza talk about how and why Greg created CrossFit and why Greg believes science is broken. ...
Gerd Gigerenzer
bSI Epistemology Camp: 2024 At his talk at the Broken Science Epistemology Camp in March 2024, psychologist Gerd Gigerenzer addresses what he calls ‘mindless statistics.’ Rather than think critically about the implications, impact, and meaning of studies, researchers are stuck in a system wh...
Greg Glassman
bSI Epistemology Camp: 2024 Greg Glassman kicked off the 2024 BSI Epistemology Camp with this presentation. Greg’s talk centers around the ‘breaking point’ from modern science to post modern science. Condemning the rise in popularity of philosophers of science like Karl Popper, Paul Feyera...

William Briggs
By William BriggsStick with me on this not-so-easy subject, because I’m going to reveal a trick used to make you “Follow the Science!”Belief is an act. Uncertainty is a state. Decision is a choice. Probability is a calculation. There is no difference between belief and decision in the sense th...

Broken Science
September 2012 book by Sharon Bertsch.Sharon Bertsch McGrayne explores the controversial theorem of Bayes' rule, and the human obsessions surrounding it. She traces its discovery by an amateur mathematician in the 1740s through its development into roughly its modern form by French scientist Pierre ...

Emily Kaplan
https://youtu.be/CfIJjKEmrd4In this video Emily explains the difference between a Bayesian approach and a frequentist approach to analyzing statistics. A Bayesian analysis looks at prior probabilities combined with data to determine the probability that the hypothesis is true. A frequentist analysis...

Emily Kaplan
https://youtu.be/scSqDj0regUSimply put, a p-value is a measure of the likelihood that the results of a study are due to the hypothesis, and not simply a result of chance. It compares the “null hypothesis,” the idea that the thing being studied has no effect, vs the “alternative hypothesis,” ...

Broken Science
October 2019 article from Scientific American.The p value plays into the human need for certainty and has led to the reproducibility crisis in may fields. Some researchers want to tweak the system of analysis, while others want to overhaul it.“P values are regularly misinterpreted, and statistical...
Broken Science
This editorial commentary by Gerd Gigerenzer and Julian Marewski discusses the dream of a universal method of inference in science. The great mathematician Gottfried Wilhelm Leibniz dreamed of a universal calculus in which all ideas could be represented by symbols and discussed without bickering. He...
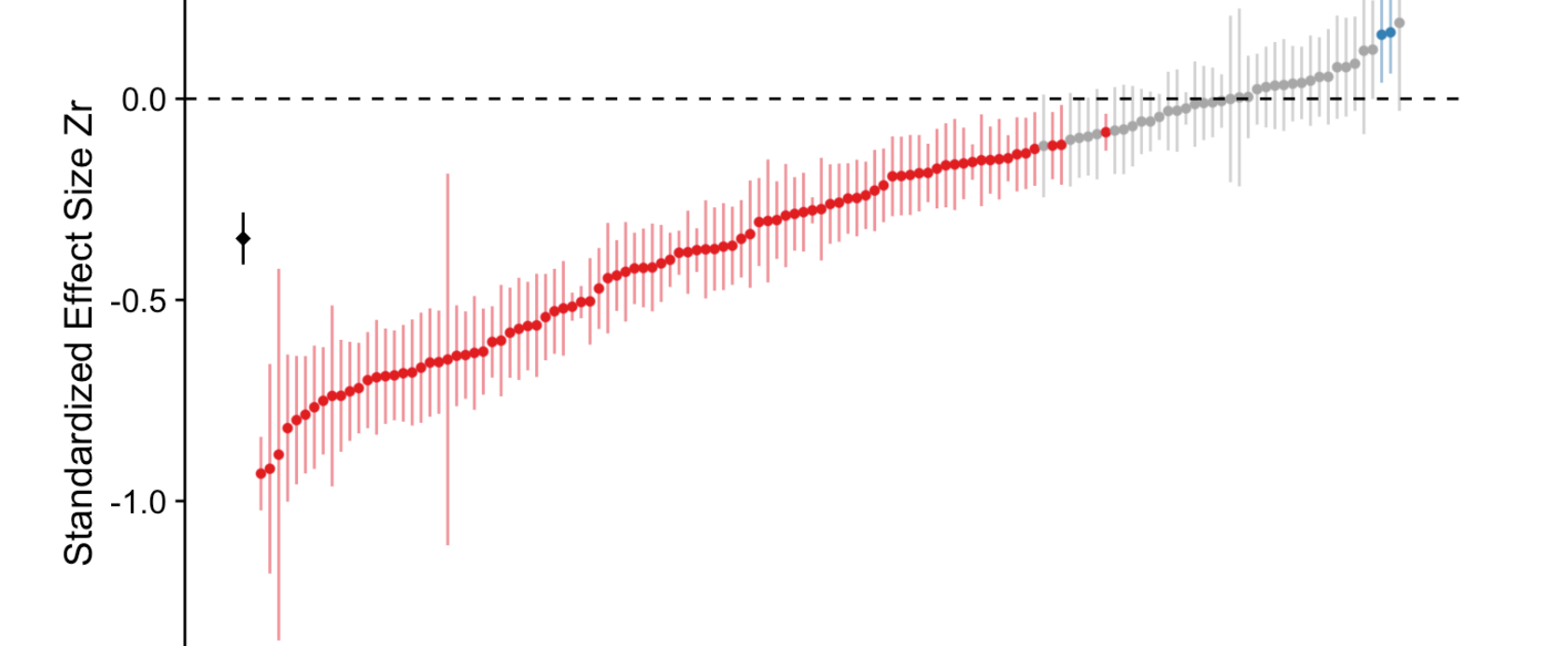
Broken Science
Gerd Gigerenzer's paper criticizes the lack of attention paid to effect sizes and the undue emphasis on null hypothesis testing in research. Despite the American Psychological Association's recommendations, effect sizes are rarely reported, hindering the computation of statistical power in tests. It...

Emily Kaplan
Induction Vs. Deduction https://www.youtube.com/watch?v=f8zKfk0RPVcIn this video of the series, Emily breaks down the difference between induction and deduction....
William Briggs
By William BriggsWe already saw a study from Nate Breznau and others in which a great number of social science researchers were given identical data and asked to answer the same question—and in which the answers to that question were all over the map, with about equals numbers answering one thing ...

Broken Science
In 2016, meta-researcher John Ioannidis and his colleagues published a paperanalyzing 385,000 studies and the abstracts of more than 1.6 million papers. Their findings show that use of the p-value has been increasing within research. Ninety-six percent of the studies analyzed reported a significant...
Gerd Gigerenzer
bSI Epistemology Camp: 2024 At his talk at the Broken Science Epistemology Camp in March 2024, psychologist Gerd Gigerenzer addresses what he calls ‘mindless statistics.’ Rather than think critically about the implications, impact, and meaning of studies, researchers are stuck in a system wh...
Greg Glassman
bSI Epistemology Camp: 2024 Greg Glassman kicked off the 2024 BSI Epistemology Camp with this presentation. Greg’s talk centers around the ‘breaking point’ from modern science to post modern science. Condemning the rise in popularity of philosophers of science like Karl Popper, Paul Feyera...
Emily Kaplan
On February 15th, Co-founder and CEO of The Broken Science Initiative, Emily Kaplan, went onto the B FIT Podcast with Connor Murphy. Connor Murphy is a celebrity trainer, Crossfit seminar staff, and trainer at Big Night Fitness.On the show Emily dives into the fundamentals of the initiative. From th...

Broken Science
Heuristic decision making refers to mental shortcuts or 'rules of thumb' used by individuals to make swift decisions, particularly under pressure or when there is a lack of detailed information. This type of thinking has been criticized as a shortcut, prone to bias, and “predictably irrational”....
Broken Science
Gerd Gigerenzer's paper criticizes the lack of attention paid to effect sizes and the undue emphasis on null hypothesis testing in research. Despite the American Psychological Association's recommendations, effect sizes are rarely reported, hindering the computation of statistical power in tests. It...

Malcolm Kendrick
By Malcolm KendrickMedicine has always been a highly conservative profession. It is both rigidly hierarchical and highly resistant to change. In large part because those at the top are perfectly happy with the status quo. People at the top usually are. It was the status quo they rode to the top of t...

Greg Glassman
Science, once a beacon of objectivity, has become marred by corruption and misuse. At BSI, we are on a mission to unravel the tyranny of broken science and those who exploit it. In this week’s episode, we hear from Greg Glassman as he dives deep into the issues of broken science and addresses the ...

Greg Glassman
https://youtu.be/8mxLebG1YLgGreg Glassman introduces the Broken Science Initiative, a new endeavor dedicated to exploring and disseminating knowledge about broken science. He discusses how a curriculum is being developed specifically for middle school students, with the goal of making intricate conc...

Broken Science
link to pdf Jeffrey A. Glassman Audio Book summary In "Evolution in Science: California Dreaming to American Awakening," author Jeff Glassman offers a deep dive into the California ...

Broken Science
In this article, Jeff Glassman argues that the validity of scientific models should be judged based on a hierarchy of conjecture, hypothesis, theory, and law. He provides definitions and examples of each, emphasizing that science relies on facts and measurements compared against standards. Glassman ...
Broken Science
link to book David Stove summary Popper and After: Four Modern Irrationalists is a book about irrationalism by the philosopher David Stove. First published by Pergamon Press in 1982, it has since been reprinted as Anything Goes: Origin...

Broken Science
link to book Roger Kimball Summary Do you believe that there is more scientific knowledge now than there was in 1901? Unless you are mad, your answer is “Yes, of course. There is vastly more known today than there was a hundred years ago. The proof of the expansion of knowledge is ...
Gerd Gigerenzer
bSI Epistemology Camp: 2024 At his talk at the Broken Science Epistemology Camp in March 2024, psychologist Gerd Gigerenzer addresses what he calls ‘mindless statistics.’ Rather than think critically about the implications, impact, and meaning of studies, researchers are stuck in a system wh...
Broken Science
April 16, 2024 article from the Brownstone Institute.Frequently unreported or classified under a different cause, deaths from prescription drugs are on the rise. Peter Gøtzsche tallies up the totals and finds the risks to be higher than previously thought.“Many people die because of errors, e.g. ...
Malcolm Kendrick
By Malcolm KendrickA few years back I was told that, in the statin clinical trials, the rate of adverse effects was always the same for the placebo, and the statin. No matter the absolute rate. This was also true for the rate of participants withdrawing from the trials. Always the same between the s...
Broken Science
April 2, 2024 article in Cancer Commons.Thomas Seyfried and his colleagues at Boston College are known for their stance on cancer being a metabolic disease, rather than a genetic one. Despite the expansion of the field of cancer genomics, Seyfried maintains that the metabolic view offers a better ex...
Russell Berger
By Russell BergerIn the 1964 suspense film 36 hours, U.S. Army Major Jefferson Pike (played by James Garner), is kidnapped by Nazis on the eve of the Allied invasion of Normandy. Pike wakes up in what appears to be a U.S. Army hospital, surrounded by soldiers and nurses that all appear to be red-blo...
Broken Science
April 3, 2024 article by Sasha Chavkin, Caitlin Gilbert, Anjali Tsui and Anahad O’Connor in The Washington Post.By sponsoring dietitians on social media and funding their own studies, General Mills and other cereal brands are shifting the narrative away from the detrimental physical effects of a h...
Greg Glassman
bSI Epistemology Camp: 2024 Greg Glassman kicked off the 2024 BSI Epistemology Camp with this presentation. Greg’s talk centers around the ‘breaking point’ from modern science to post modern science. Condemning the rise in popularity of philosophers of science like Karl Popper, Paul Feyera...
Broken Science
March 26, 2024 Article by Sanjana Friedman on Pirate Wires.The state's math framework is strongly influenced by the academic work of Jo Boaler, now accused of significantly distorting citations in research underpinning the framework..“Boaler first made a name for herself in the mid-2000s by advoca...
William Briggs
By William BriggsA new study came out that claimed intermittent fasting is bad for you. This shocked a lot of people. Here’s one of the hot headlines: “8-hour time-restricted eating linked to a 91% higher risk of cardiovascular death“.Ninety one percent? Dude. That’s a lot. Makes it sound l...
Malcolm Kendrick
By Malcolm KendrickAs everyone knows, a placebo is an inactive ‘sugar’ pill. Except when it isn’t. Which is almost always. Here, from 2010, is an article about research on placebos carried out by Dr Beatric Golomb [1]."What rules are there about what goes into placebos?Despite carrying moniker...
Broken Science
March 07, 2024 commentary in the Journal of Occupational and Environmental Hygiene and a documentary by the Health Physics Society.From corruption in governing bodies to deliberate misrepresentations by researchers, this series takes the first steps to correct the scientific record in the field of c...
Emily Kaplan
Februaury 28, 2024 episode of the Dr. Drew PodcastDr. Drew and Emily call attention to the flaws in the current state of modern science. Emily and Drew discuss the Dana-Farber scandal, the cost/benefit of going to college, the do-or-die culture in science, and the lack of curiosity among journalists...
